
🐌
Yours truly is not an expert in compilers but does enjoy diving into this topic and learning something new from time to time.
Why write another toy compiler? First and foremost, because it’s a lot of fun. Also learning a great deal along the way comes with the package. Learning not only in terms of technical skills but also in terms of managing a project’s scope, complexity, and ultimately delivering a working program implementing the original idea.
As someone who finds these reasons compelling, I developed a hobby compiler too. Read on to find out about things that might set this one apart.
Code calculating a portion of the Fibonacci sequence looks like this:
class Fib() extends IO() {
def fib(x: Int): Int =
if (x == 0) 0
else if (x == 1) 1
else fib(x - 2) + fib(x - 1);
{
var i: Int = 0;
while (i <= 10) {
out_string("fib("); out_int(i); out_string(") = ");
out_int(fib(i));
out_nl();
i = i + 1
}
};
}
class Main() {
{ new Fib() };
}Or take a look at the sources of Conway’s Game of Life
Cool 2020 is a small Scala subset which can be implemented in a time-frame reasonable for a hobby compiler. Although concise, the language is quite expressive — the features include:
These represent exciting compiler design and implementation challenges. Cool 2020 is statically typed, which again leads to interesting implications for design and implementation.
The language being a Scala subset, tools for Scala code syntax highlighting, formatting, and editing work out of the box. A Cool 2020 program can be (with just a little bit of scaffolding code) compiled by a Scala compiler or executed in an online playground.
The two supported hosts are x86-64 Windows and Linux. And in general,
the project is based on cross-platform technologies. The compiler itself
runs on .NET. The GNU tools as and ld are
available on Linux and Windows (and many, many other, of course). The
language’s runtime is implemented in assembly and is split up into three
parts: the majority of code is in a common source file, Windows-specific
bits, and Linux-specific bits that are responsible for calling Windows
API and Linux system functions reside in their respective source
files.
The language’s runtime library implements a simple generational garbage collector.
Approximately 312 automated tests make up the test suite. One nice consequence of generating native executables is an automated test can compile a program, run it, and compare the program’s output to the expected values. Out of the 288 tests, there are 39 that do exactly that.
Here’s how compiling a hello world looks like.
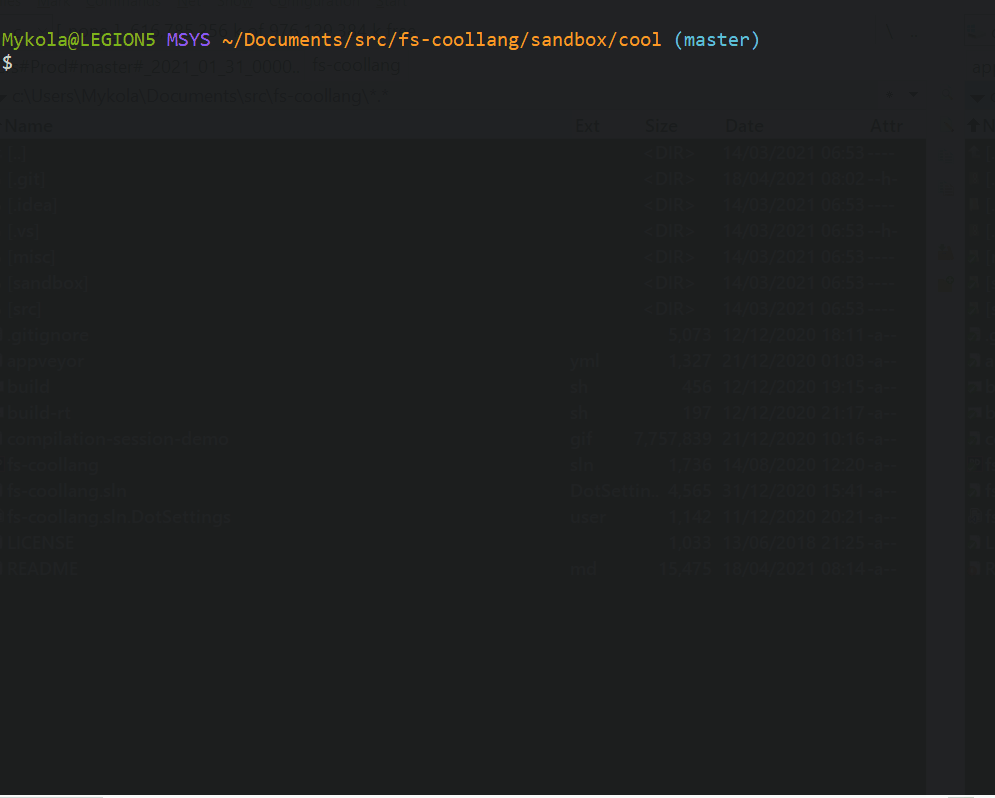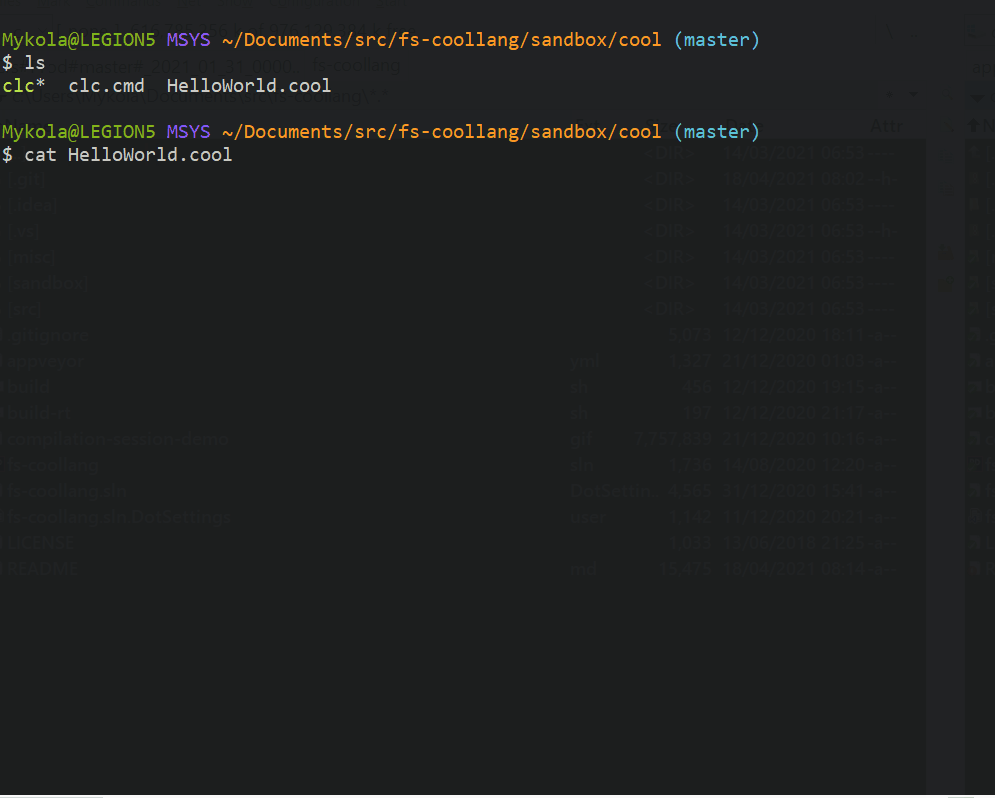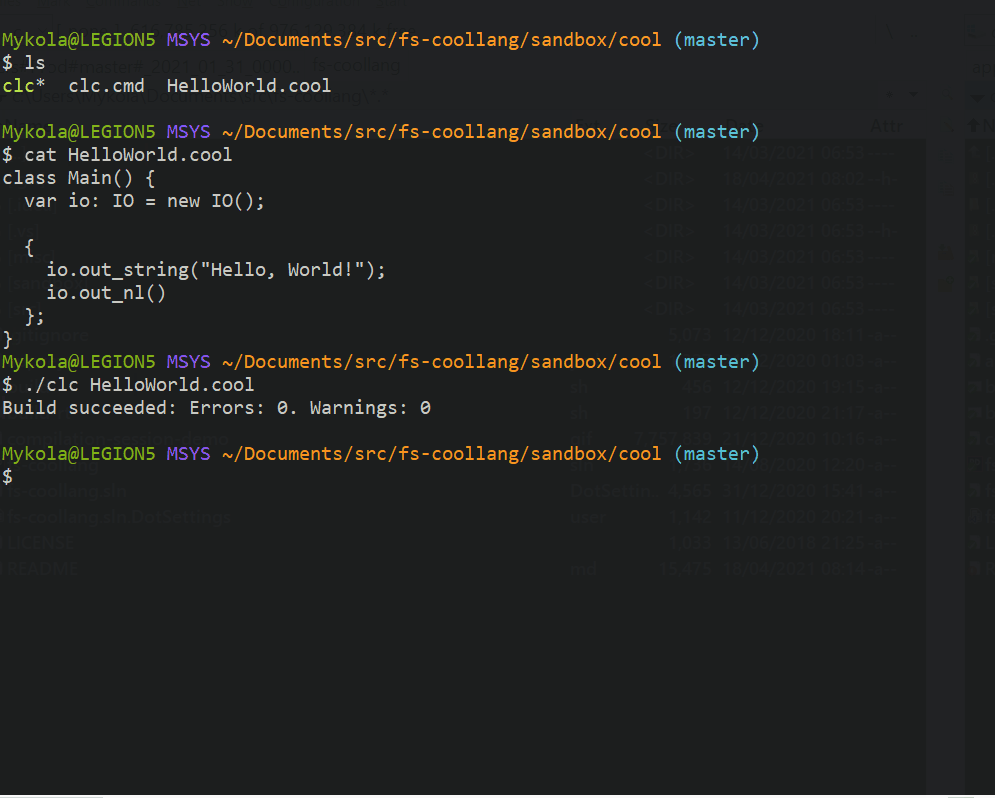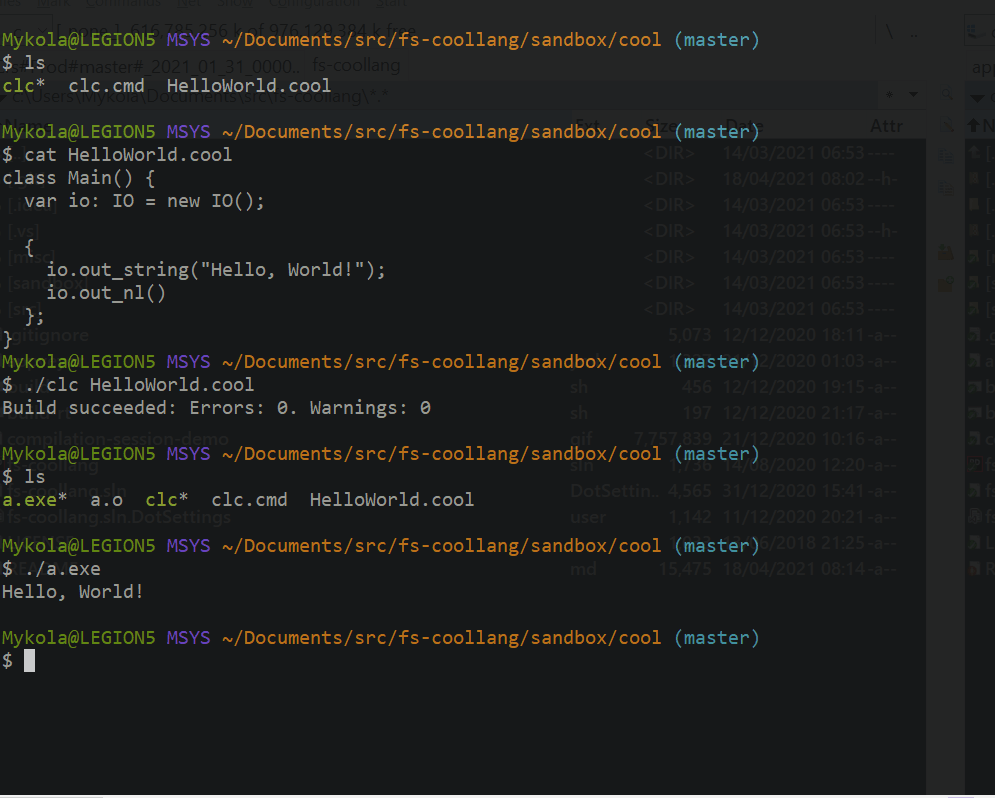
Reporting errors encountered in the user’s code is an essential function of a compiler. Spending some time upfront to think though this aspects of compiler design is well worth it. As the decision has a significant impact on the compiler’s mechanics and code. So, it’s great to have a set of explicit, coherent assumptions in mind when working on the implementation.
The compiler can display an error message and stop the translation once it runs into the first error. This is arguably the simplest error-handling strategy to implement. It has an obvious downside. If a program contains multiple errors, this strategy makes the user go through an equal number of correct the error / restart compilation iterations to catch them all. The user experience might not necessarily be ideal in this case.
At the other end of the spectrum, a compiler can attempt to identify and report as many errors in the code as possible within a single run. When such a compiler detects an error it informs the user but, instead of stopping, it keeps going over the code. With the aim of keeping the number of times the user has to restart compilation to a minimum — only one restart is required in the best-case scenario. While this strategy sounds a lot nicer it’s not without problems either.
It leads to a notable increase in the compiler’s code complexity, as the compiler has to employ heuristics reducing cascading errors. What’s a cascading error? In the Scala code sample below, there’s one error — the closing parenthesis is missing in line 2.
class CascadingError {
def force(: Unit = {
};
}But the Scala compiler diagnoses two errors. After seeing the first, real one it gets “confused” and reports the second error in line 3 where there is no actual problem with the code. This is an example of cascading error.
CascadingError.scala:2: error: identifier expected but ':' found.
def speak(: Unit = {
^
CascadingError.scala:3: error: ':' expected but ';' found.
};
^In some cases, cascading errors make diagnostic messages so noisy, users start looking for a way to make the compiler stop after the first encountered error. The effort necessary to tell real errors from cascading errors can degrade the user experience to such a degree as to defy the entire point of reporting maximum number of error in one go.
Some compilers aim to integrate the strong sides of both approaches by following a middle-of-the-road error handling strategy. Translation of a program from the input language into the target one typically happens over a number of stages. For an educational compiler these stages can look like this.
(What about a production-grade compiler? C# compiler has more than 20 compilation stages)
The idea is to diagnose as many errors in the input code as possible within one compilation stage. The key difference with the approach of detecting maximum errors per a compilation is that the next compilation stage will only start if no errors are found at the current one.
At the lexical analysis stage, if the lexer encounters a portion of the source that doesn’t correspond to any valid token, an error is reported to the users and lexing continues. But parsing isn’t going to start, the compiler will stop once lexing is complete.
Similarly, if the parser encounters a syntactic error, it’s reported to the user and parsing continues. Once syntactic analysis is complete, the compiler will stop instead of moving on to the semantic analysis stage.
In contrast, the C# compiler performs lexing and parsing at the same time. If the lexer doesn’t recognize a token, the parser handles this scenario and keeps going anyway. But semantic analysis will not start if lexical or syntactic errors have been encountered in the input code. In such a case, translation terminates.
And so on.
A great example of going this way is the C# compiler. Here’s a short description Eric Lippert gave on StackOverflow:
Briefly, the way the compiler works is it tries to get the program through a series of stages […]
The idea is that if an early stage gets an error, we might not be able to successfully complete a later stage without (1) going into an infinite loop, (2) crashing, or (3) reporting crazy “cascading” errors. So what happens is, you get one error, you fix it, and then suddenly the next stage of compilation can run, and it finds a bunch more errors.
[…]
The up side of this design is that (1) you get the errors that are the most “fundamental” first, without a lot of noisy, crazy cascading errors, and (2) the compiler is more robust because it doesn’t have to try to do analysis on programs where the basic invariants of the language are broken. The down side is of course your scenario: that you have fifty errors, you fix them all, and suddenly fifty more appear.
Finally, let’s see how this idea is represented in the
C# compiler’s source code. The method CompileAndEmit of
the class Microsoft.CodeAnalysis.CommonCompiler coordinates
compilation of C# and VB.NET source code.
/// <summary>
/// Perform all the work associated with actual compilation
/// (parsing, binding, compile, emit), resulting in diagnostics
/// and analyzer output.
/// </summary>
private void CompileAndEmit(/*[...]*/)
{
analyzerCts = null;
reportAnalyzer = false;
analyzerDriver = null;
// Print the diagnostics produced during the parsing stage and exit if there were any errors.
compilation.GetDiagnostics(CompilationStage.Parse, includeEarlierStages: false, diagnostics, cancellationToken);
if (HasUnsuppressableErrors(diagnostics))
{
return;
}
// [...]
}Right away, we notice the invocation of
compilation.GetDiagnostics with
CompilationStage.Parse. The invocation is followed by a
check HasUnsuppressableErrors to determine whether the
compilation stage complete successfully and should the compilation move
on to the next stage or stop. If you keep looking through the code of
CompileAndEmit you’ll find more spots that perform a call
to HasUnsuppressableErrors(diagnostics) and based on the
result decide to stop or carry on with the compilation.
It’s easy to get hung up on parsing theory as it’s a fascinating area of computer science. But try and resist the temptation as it gets real complex really fast. And the thing is, coding up a recursive descent parser takes very little knowledge of the theory. Of course, you can always come back later and study parsing in great details. Actually, first getting a feel for it by doing is going to be a great help in grasping the theory later.
Using a parser generator tool or a parser combinator library might sounds like a good way to save time and effort vs writing a parser by hand. But writing a hand-crafted parser might turn out easier than it seems from the outset. Once you get into the groove, you may realize that while it does take more typing, than using a tool wood, in return you get straightforward handwritten code that is easy to reason about and debug. And if you hit a special case, you just add a branch to handle it instead of fighting with a tool which might or might not be well documented.
Again, I cannot recommend “Crafting Interpreters” enough for a guide on implementing a parser.
It’s hard to underestimate the importance of having a working example to look at and fully comprehend. Here goes a couple:
Please, keep in mind, the last two are much bigger than
8cc and chibicc and don’t have easy of
exploring their sources as an explicit goal.
An impressive thing to note is production-grade, major-league
language implementations like GCC, Clang,
Roslyn (C# and VB.NET compiler), D,
Rust, Swift, Go,
Java, V8, and TypeScript use
hand-crafted recursive descent parsers too. So, if you decide to go down
this route, your experience will actually be closer to that of
professional compiler developers :)
The compiler translates the source code down to x86-64 assembly. Then
GNU as and ld come into play to build a native
executable from the assembly.
Many educational compilers emit MIPS assembly, and although it’s possible to run it using an emulator, to me, running a native executable produced by your own compiler feels much more rewarding.
I also prefer emitting assembly instead of, for instance, C. It helps understand the inner workings of various things we often take for granted when coding in high-level languages:
On the other hand, someone enthusiastic about compilers isn’t unlikely to be interested in going even deeper, down to the level of binary machine code and linking. I decided to stop short of working on these undeniably enticing subjects, to focus on building a working compiler first.
All in all, assembly code native to your platform is a sweet spot for translation. It gets you close-enough to the metal to learn how high-level languages do their magic. But is abstract enough to avoid getting distracted by somewhat orthogonal subjects.
Chapter 11 – Code Generation of Introduction to Compilers and Language Design is a great discussion of a basic approach to assembly generation.
Examining the sources of chibicc: A Small C Compiler or 8cc C Compiler is an excellent opportunity to see assembly-generating code in action.
The assembly contains constant names instead of magic numbers where possible. The number of places using constant names is planned to grow.
The compiler tries to generate useful names for integer and string
constants. For example, INT_0 corresponds to an integer
value 0, INT_42 — to 42.
If a string does not contain any characters illegal in an identifier
and is not too long, the corresponding constant name will contain this
string’s value. To illustrate, a constant name for the string
"Boolean" is going to be STR_8_Boolean.
The emitted assembly code contains a lot of hopefully useful comments. Some of the comments indicate the point in the source code that the assembly corresponds too. The idea here is to help understand the assembly and relate it back to the source code as much as possible.
.text
# ../CoolPrograms/Runtime/Fibonacci.cool(1,7): Fib
.global Fib..ctor
Fib..ctor:
pushq %rbp
movq %rsp, %rbp
subq $64, %rsp
# store actuals on the stack
movq %rdi, -8(%rbp)
# store callee-saved regs on the stack
movq %rbx, -24(%rbp)
movq %r12, -32(%rbp)
movq %r13, -40(%rbp)
movq %r14, -48(%rbp)
movq %r15, -56(%rbp)
# actual #0
movq -8(%rbp), %rbx
subq $8, %rsp
movq %rbx, 0(%rsp) # actual #0
# load up to 6 first actuals into regs
movq 0(%rsp), %rdi
# remove the register-loaded actuals from stack
addq $8, %rsp
call IO..ctor # super..ctor
movq %rax, %rbx # returned value
# ../CoolPrograms/Runtime/Fibonacci.cool(8,18): 0
movq $INT_0, %rbx
# ../CoolPrograms/Runtime/Fibonacci.cool(8,5): var i: Int = 0
movq %rbx, -16(%rbp) # i
.L6_WHILE_COND:
# ../CoolPrograms/Runtime/Fibonacci.cool(9,12): i
movq -16(%rbp), %r10 # i
# ../CoolPrograms/Runtime/Fibonacci.cool(9,17): 10
movq $INT_10, %r11In short, programs use processor registers to temporarily store variable and expression values. This post won’t dig any deeper than that, as by the time you get to implementing register allocation, you’ll in all likelihood have read longer descriptions by people who are actually good at explaining things.
Anyway, something to keep in mind, coding up register allocation can be a rather involved exercise. Register allocation in production compilers is a matter of scientific research. But there’s an extremely simple approach that is great to get a compiler up and running and can get it surprisingly far. It’s laid out in that same “Chapter 11 – Code Generation”:
[Y]ou can see that we set aside each register for a purpose: some are for function arguments, some for stack frame management, and some are available for scratch values. Take those scratch registers and put them into a table […] Then, write
scratch_allocto find an unused register in the table, mark it as in use, and return the register numberr.scratch_freeshould mark the indicated register as available.scratch_nameshould return the name of a register, given its numberr. Running out of scratch registers is possible, but unlikely, as we will see below. For now, ifscratch_alloccannot find a free register, just emit an error message and halt.
Translating an expression is an exciting problem as there is no way
to directly encode a complex expression like this
(a + b) == (c + d) into assembly code — as usually an
assembly instruction takes one, two operands.
A general pattern here is to break down a complex expression into smaller subexpressions according to the operations priorities. Each subexpression should be small enough to have a straightforward mapping into assembly. Then the compiler emits instructions to evaluate a part’s result and store this result into a register allocated to temporarily hold it.
This way, when dealing with a subexpression which has child subexpressions of its own, the compiler simply looks up the names or registers allocated to hold the results of the child subexpressions. With these registers at hand, it’s straightforward to generate instructions corresponding to the subexpression’s operation “replacing” the child subexpressions with their respective register names.
This page discusses expression translation in more detail and walks the reader through a specific example.
An implementation of educational language relies on a number of
built-in functions, classes, and objects. Some of these are available to
the user directly, such as ChocoPy’s print function or Cool
2020’s IO class. References to other built-ins can only be
injected into a program by the compiler — for example, to allocate the
memory for a new object or abort the execution in case things have gone
off the rails.
The only readily available runtime implementation for an educational language I’m aware of is written in MIPS assembly for the language COOL designed by Alex Aiken used in his famous online course.
(Notice, while the names Cool 2020 and COOL sound confusingly similar, the languages themselves are distinct: Cool 2020 is a Scala subset and COOL is an invention of Alex Aiken. The name Cool 2020 is a tribute to Aiken’s COOL.)
Examining COOL runtime’s MIPS code provides enough insights to implement a similar one for a different “client” language and dialect of assembly. This is how I came up with a runtime for Cool 2020 in x86-64 assembly. It’s written in an extremely naive and unoptimized way, but gets the job done.
The runtime is made up of these assembly source files:
Any,
String, ArrayAny, etc resides in this
fileInt objectsIn particular, rt_common.s contains a compiled program’s
process entry point responsible for
Main and
invoking its constructor.The process entry point’s logic expressed in pseudocode follows.
def main () = {
. Platform .init();
new Main();
.Platform.exit_process(0)
}And here is the actual assembly code.
.global main
main:
MAIN_OBJ_SIZE = 8
MAIN_OBJ = -MAIN_OBJ_SIZE
PAD_SIZE = 8
FRAME_SIZE = MAIN_OBJ_SIZE + PAD_SIZE
pushq %rbp
movq %rsp, %rbp
subq $FRAME_SIZE, %rsp
call .Platform.init
# The base of stack -- to stop checking for stack GC roots at.
movq %rbp, %rdi
call .MemoryManager.init
# A class 'Main' must be present in every Cool2020 program.
# Create a new instance of 'Main'.
movq $Main_PROTO_OBJ, %rdi
call .Runtime.copy_object
# Place the created `Main` object on the stack
# to let the GC know it's not garbage.
movq %rax, MAIN_OBJ(%rbp)
# 'Main..ctor' is a Cool2020 program's entry point.
# Pass a reference to the newly created 'Main' instance in %rdi.
# Invoke the constructor.
movq %rax, %rdi
call Main..ctor
xorq %rdi, %rdi
jmp .Platform.exit_processYes, yes, you read that right, interpreters. Crafting Interpreters by Robert Nystrom is simply a brilliant book, which despite its name can serve as a great introduction to compilers. Compilers and interpreters have a lot in common and by the time you get to the interpreters-specific topics, you’ll gain a ton of useful knowledge. In my opinion, the explanations on general programming language implementation concepts, lexing, and parsing are downright the best in class.
Introduction to Compilers and Language Design by Douglas Thain is really accessible and doesn’t assume any preexisting compilers knowledge. It teaches all the basics necessary to build a compiler: from lexing and parsing to a program’s memory organization and stack management to assembly generation. It’s self-contained and takes a hands-on approach: you’ll end up with a working compiler if you choose to following the book through. If later you feel like digging into more advanced compiling techniques, you’ll have a solid foundation to build upon.
Both are freely available online. (I encourage you to consider buying the paid versions of the books though, if you can, to support the authors).
Who’s gonna watch a Fortnite stream on Twitch, when Immo Landwerth is coding up a compiler live on YouTube?! Apart from all the usual compiling topics, the series touch upon adding a basic debugger support, so that it’s possible to step through the source of a compiled program. Immo is an awesome educator and their code is accessible and simply beautiful. You can explore it in the project’s github repo.
A free self-guided online course from Cornell University. Goes in depth on IR and optimizations but is very accessible at the same time. Again, cannot recommend highly enough. CS 6120: Advanced Compilers: The Self-Guided Online Course.
A talk on intermediate representations (IR). Previous knowledge is not required. What’s so cool about this talk is it’s built around one of the most widely used IR — LLVM IR. 2019 EuroLLVM Developers’ Meeting: V. Bridgers & F. Piovezan “LLVM IR Tutorial - Phis, GEPs …”.
While there’s no way around studying a bit of theory before getting down to coding, do not start with classics textbooks like the Dragon Book, or “Modern Compiler Implementation”. These are great, and you can always come back to them later, when you’re better prepared to take the most out of them.
That said, it’s way more productive to read ones geared toward beginners first. The ones I’d opt for are listed in the Learning resources section.
Go with an existing educational language instead, and focus on learning about compilers.
Compiling is a huge field. You’ll encounter seemingly endless choices, techniques, and opinions each step of the way. At times it’s hard not to give in to the temptation of going down the rabbit hole of researching all kind of ways of implementing a compilation stage or algorithm. I believe keeping the project’s scope as narrow as possible is a recipe for actually getting through to a working compiler.
Stick to straightforward simple ways of doing things at first. Consider writing down all the interesting links and nuggets of information you come across and setting them aside for a time. Once you finally make it to the other side, you can start going through your notes and replacing portions of the code with more advanced algorithms or extending it with additional functionality.
Good luck!